16 Jul 2025
Data oriented decision making is bullshit.
People are hiding behind data, statistic and all those fancy reports to avoid any possible liabilities. Maybe this is how to become a “professional”, if so, then professionalism is also a lie.
为什么说把握主要矛盾在道德上是可以接受的
叠甲:仅为记录针对我你好我好大家好的老好人心态看待问题时曾经无法说服自己进行抓大放小的决策心态以及后续解开心结的结论。
因为主要矛盾在存在的所有矛盾中具有支配作用,所有的其他矛盾都会受其进展的影响。大的小的一把抓当然是理想情况,但在资源有限的情况下,要有魄力暂时放弃解决非主要的矛盾。并且大多数情况下随着主要矛盾被投入资源进行解决,事态的发展会让其他矛盾一起好起来。
08 Jul 2025
I found that building something useful and helpful around our ALMIGHTY LLM is actually a good direction that follows my ultimate tenet: liberation of people. If we can utilize AI tools to help us work, why sit in a cell 10 hours a day?
As a programmer, software engineer, or whatever it’s called, the first thing that comes to my mind is to use LLMs in coding tasks, and it has done well. Naturally, an idea emerges: I want it to become a super assistant for my work, liberating myself from endless tedious tasks.
Thinking of that, I came up with a roadmap that could lead us to success!
A detailed explanation is below the diagram, along with some update notes.
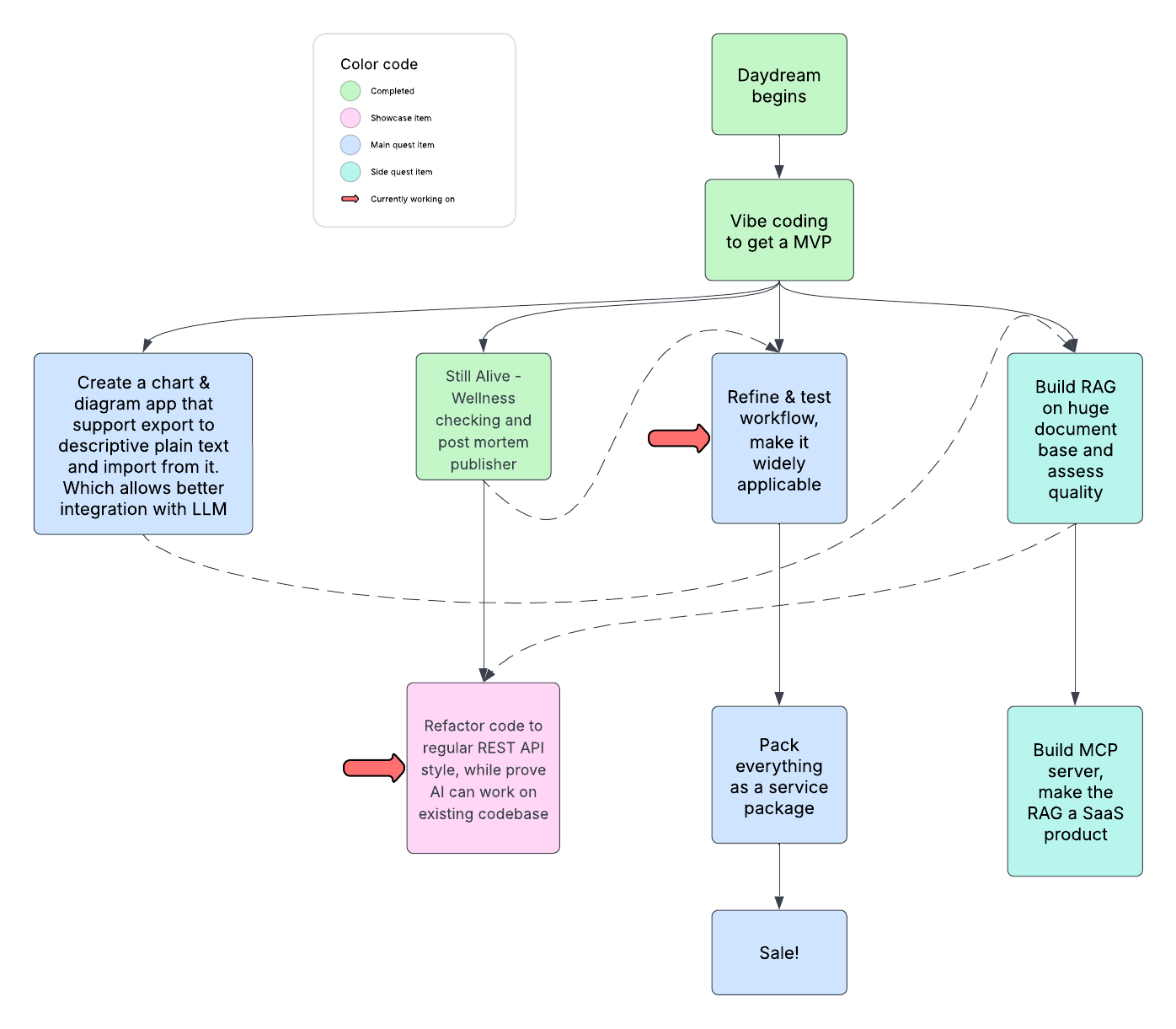
Chart & Diagram App
Background
LLMs can’t understand flowcharts and arrows in charts correctly. In my work, there are tons of documents that are chart/diagram heavy. So if we want to use LLMs to help us do our work, they need to understand these things.
Approach
To let LLMs understand the spatial features of diagrams, we need to describe them in plain text. I’m thinking of a UML-like format, but leaning more toward natural language. Also, we need to support generating graphics from this kind of formatted text, so that we can have LLMs draw diagrams for us. Layout is surely lost during the export process, but that’s fine.
RAGs
Questions
- How do we chunk the document without sacrificing the integrity of the doc? If a piece of a document is highly related to the question, the rest of the document should have a raised relativity.
- How do we chunk code bases? First of all, we should chunk by AST tree. Then, should we insert line numbers or filenames into each chunk? Or can we do something like another layer of index, where we summarize what the code file is doing in natural language, then embed the “description index”?